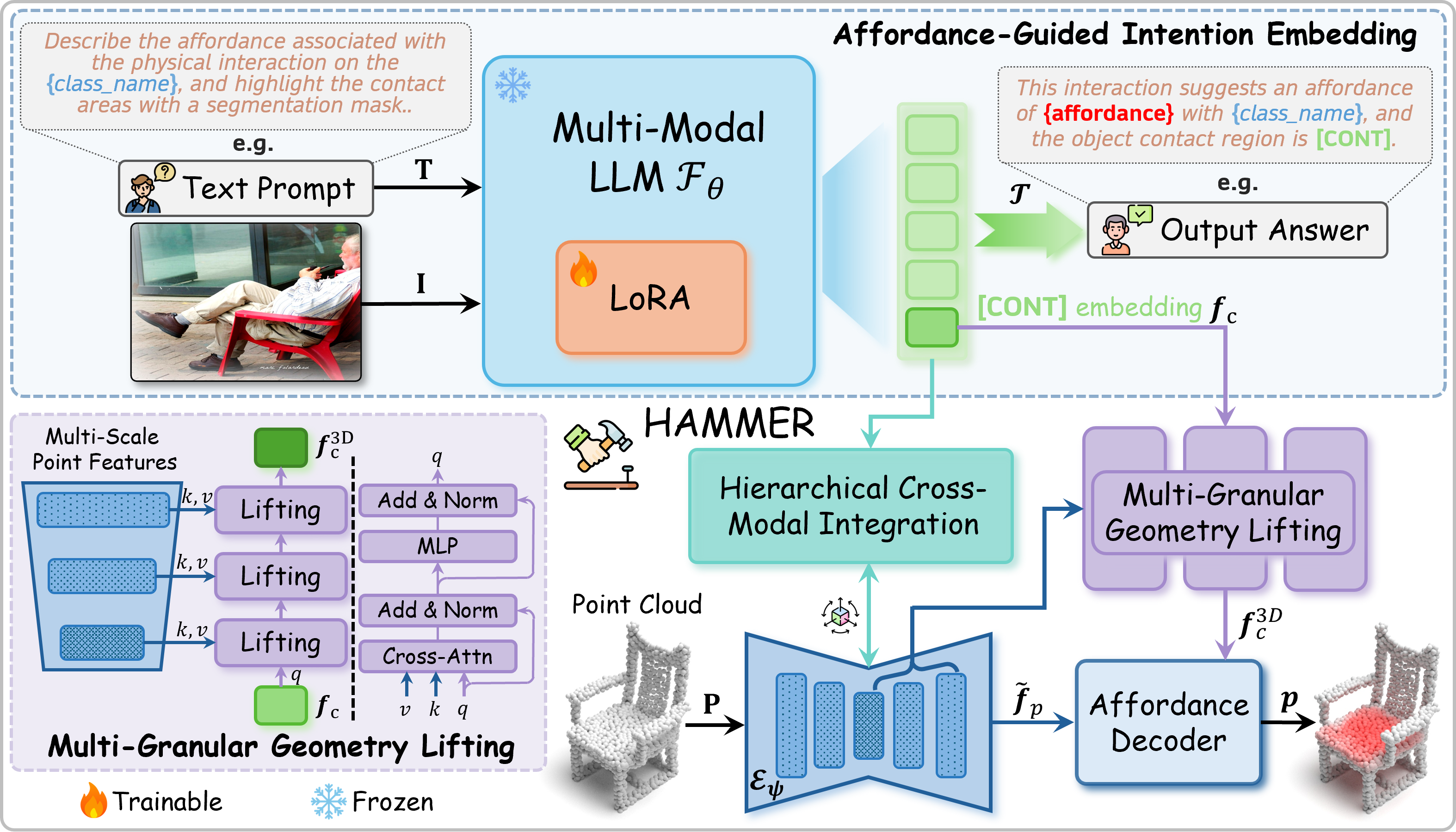
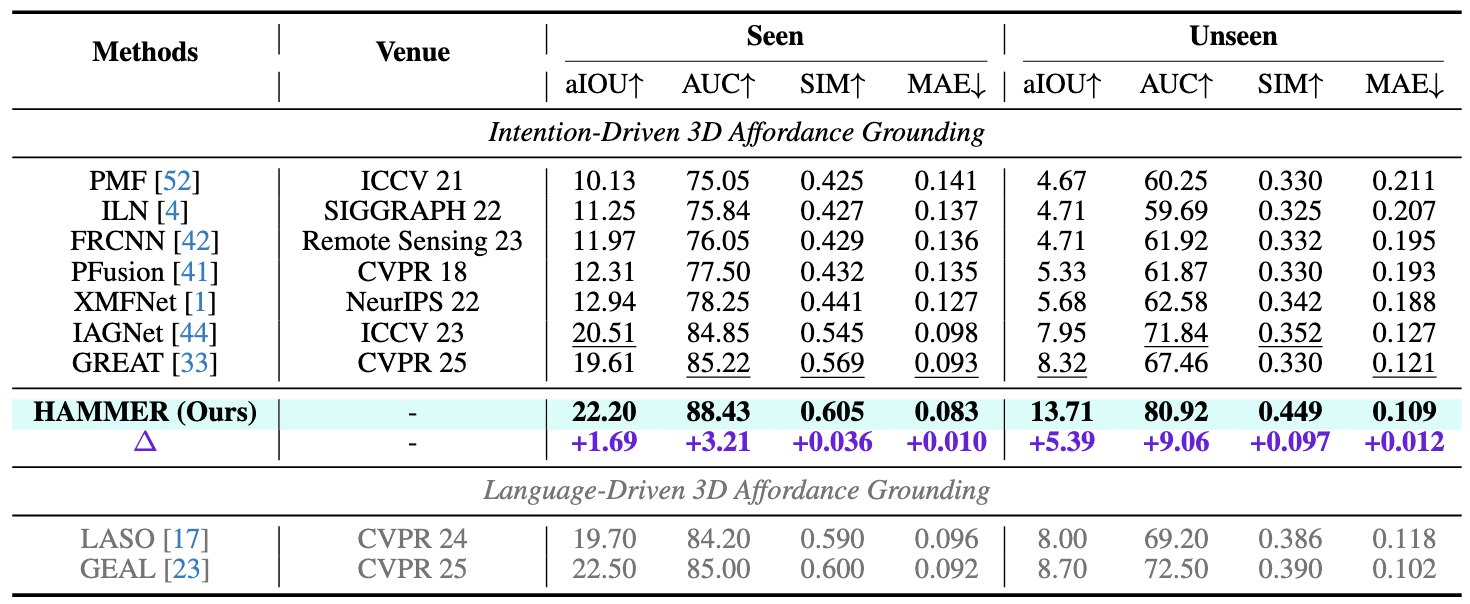
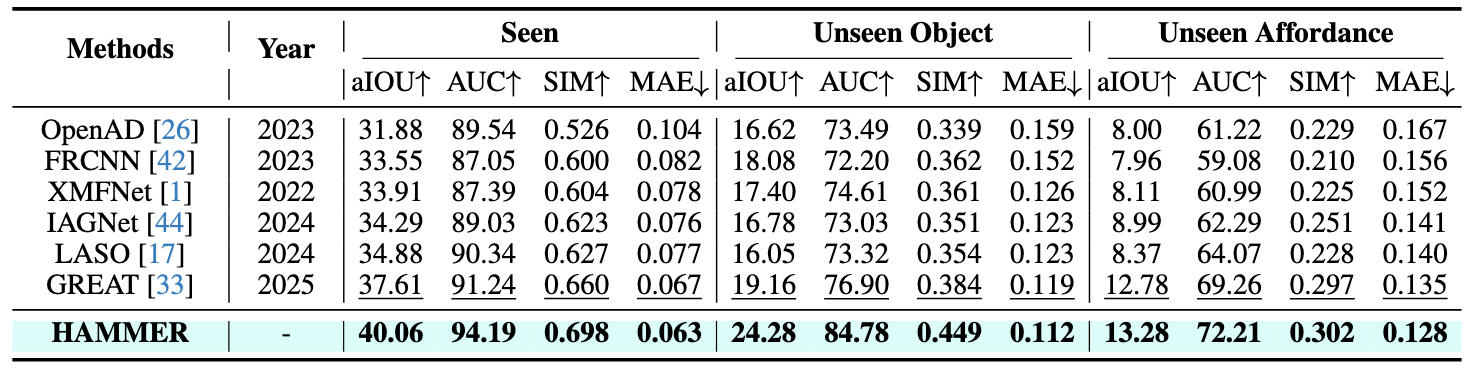
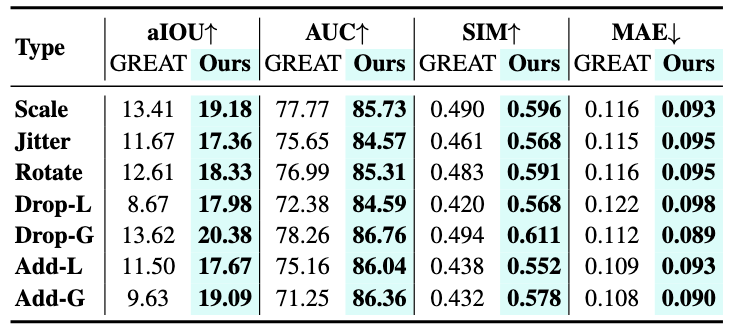
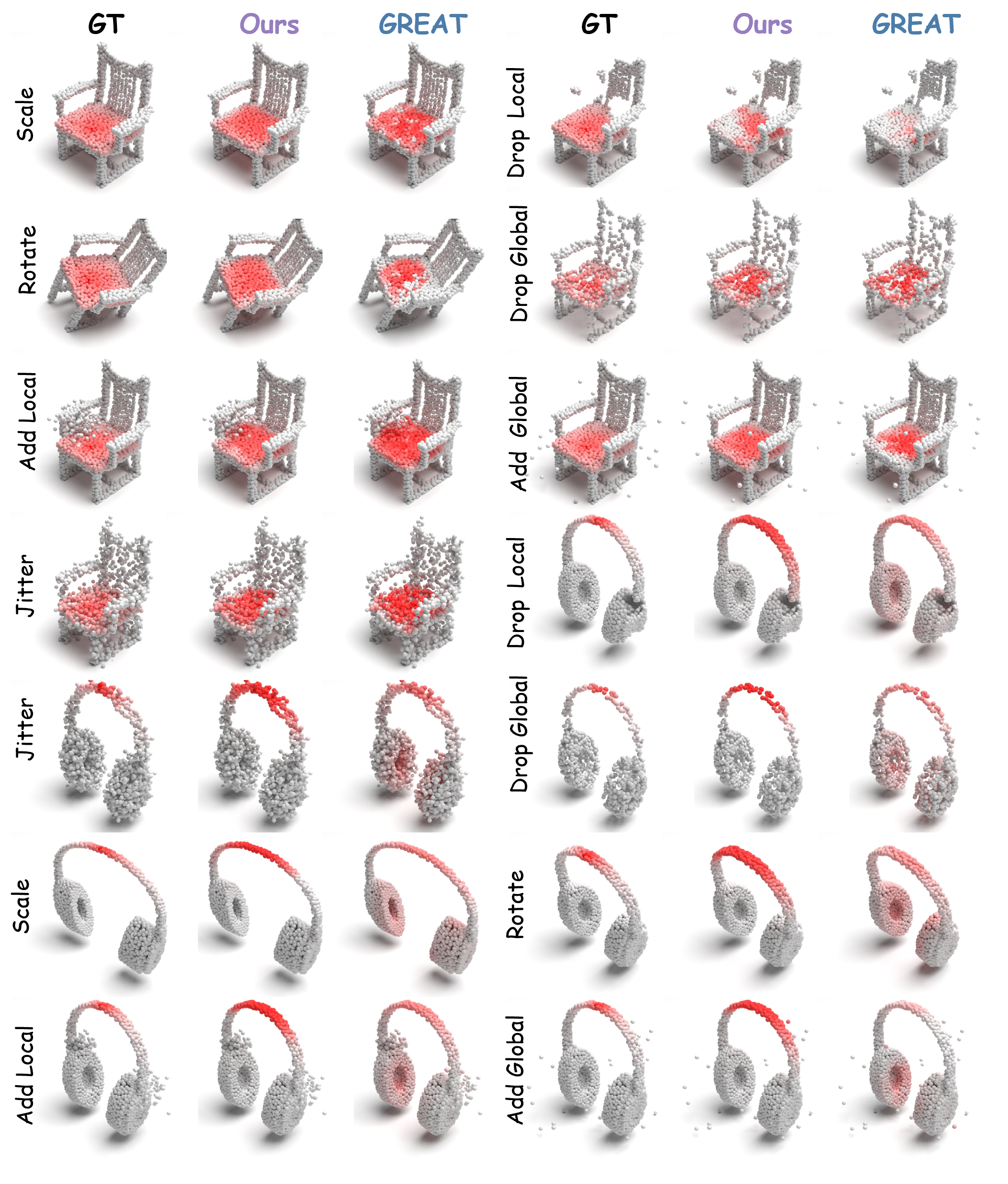
Humans commonly identify 3D object affordance through observed interactions in images or videos, and once formed, such knowledge can be generically generalized to novel objects. Inspired by this principle, we advocate for a novel framework that leverages emerging multimodal large language models (MLLMs) for interaction intention-driven 3D affordance grounding, namely HAMMER. Instead of generating explicit object attribute descriptions or relying on off-the-shelf 2D segmenters, we alternatively aggregate the interaction intention depicted in the image into a contact-aware embedding and guide the model to infer textual affordance labels, ensuring it thoroughly excavates object semantics and contextual cues. We further devise a hierarchical cross-modal integration mechanism to fully exploit the complementary information from the MLLM for 3D representation refinement and introduce a multi-granular geometry lifting module that infuses spatial characteristics into the extracted intention embedding, thus facilitating accurate 3D affordance localization. Extensive experiments on public datasets and our newly constructed PIADv1-C benchmark demonstrate the superiority and robustness of HAMMER compared to existing approaches.